Last updated: August 8th 2025
Categories: IT Knowledge
Author: Marcus Fleuti
How to Crack KDBX4 KeePass Databases with John the Ripper
Introduction: The Challenge of KDBX4 Password Recovery
KeePass password databases have evolved significantly over the years, with KDBX4 representing the latest and most secure format. Unlike older KeePass formats, KDBX4 implements Argon2, a memory-hard key derivation function specifically designed to resist GPU-based password cracking attempts. This guide provides a comprehensive approach to recovering lost KDBX4 passwords using John the Ripper, the industry-standard password recovery tool.
While password recovery for KDBX4 databases is intentionally difficult—achieving only 5-50 passwords per second even on modern hardware—there are legitimate scenarios where this knowledge is essential: recovering your own forgotten master password, security auditing, or penetration testing with proper authorization. This guide will walk you through the entire process, from compiling John with GPU support to optimizing your wordlists for maximum efficiency.
Understanding KDBX4 Security: Why It's So Resistant to Cracking
KDBX4 databases employ Argon2, winner of the Password Hashing Competition in 2015. This algorithm is specifically engineered to be:
- Memory-hard: Requires significant RAM per hash computation (typically 64MB or more)
- Parallelization-resistant: Cannot efficiently parallelize single hash calculations
- GPU-resistant: Prevents the massive speedups GPUs typically provide for other algorithms
To put this in perspective, while GPUs can crack billions of MD5 hashes per second, KDBX4 with Argon2 limits even high-end GPUs to mere dozens of attempts per second. On a 32-core AMD CPU, you might see only 5 passwords per second, while a GPU might reach 27-50 p/s—a far cry from the acceleration seen with other hash types.
Prerequisites: Setting Up Your Environment
Installing Required Dependencies
Before compiling John the Ripper with OpenCL support for GPU acceleration, install these essential packages on Ubuntu/Debian systems:
sudo apt update
sudo apt install build-essential libssl-dev libgmp-dev libpcap-dev \
libbz2-dev zlib1g-dev git opencl-headers ocl-icd-opencl-dev \
pocl-opencl-icd
# For NVIDIA GPUs:
sudo apt install nvidia-opencl-dev
# For AMD GPUs:
sudo apt install mesa-opencl-icdCompiling John the Ripper with OpenCL Support
Clone and compile the latest John the Ripper jumbo version with full GPU support:
# Clone the repository
git clone https://github.com/openwall/john.git
cd john/src
# Configure (configure routine detects the openCL availability automatically)
./configure
# Compile using all available CPU cores
make -j$(nproc)
# The compiled binary will be in ../run/
cd ../run
./john --list=formats | grep --color -i keepassYou should see both KeePass (CPU) and KeePass-Argon2-opencl (GPU) formats listed if compilation was successful.
Extracting Hashes with keepass2john
Warning: Avoid Outdated keepass2john Repositories
Important: The standalone repository at https://github.com/ivanmrsulja/keepass2john is outdated and should not be used. It only supports legacy KeePass 1.x and 2.x database formats without modern encryption. The keepass2john tool integrated directly into John the Ripper's jumbo version provides full support for KDBX4 and encrypted headers.
The above described John The Ripper repository (https://github.com/openwall/john.git) contains an updated keepass2john tool with which the necessary password hash on a KDBX4 database can be created.
John the Ripper includes the keepass2john utility for extracting crackable hashes from KeePass databases:
# Basic usage - enter /run/ folder and execute the keepass2john tool:
./keepass2john database.kdbx > database.hash
# Example with keyfile
./keepass2john -k keyfile.key database.kdbx > database.hash
# Multiple databases
./keepass2john *.kdbx > all_databases.hashBuilding Optimized Wordlists with SecLists
Downloading SecLists Password Collection
SecLists provides one of the most comprehensive password collections available. Use sparse checkout to download only the passwords folder:
# Initialize sparse clone
git clone --filter=blob:none --no-checkout https://github.com/danielmiessler/SecLists.git
cd SecLists
# cd into the so-created SecLists folder and configure sparse checkout for Passwords folder only like this:
git sparse-checkout init --cone
git sparse-checkout set Passwords
# Download the Passwords folder
git checkout masterThis approach saves bandwidth and disk space by downloading only the 500MB+ password collection instead of the entire 2GB+ repository.
Combining and Deduplicating Wordlists
SecLists contains numerous password files with significant overlap. Use this script to combine and deduplicate them efficiently:
#!/bin/bash
# Wordlist Combiner Script
# Recursively finds all .txt files, combines them, and removes duplicates
# Usage: ./combine_wordlists.sh [directory] [output_file]
set -euo pipefail
# Default values
SEARCH_DIR="${1:-.}"
OUTPUT_FILE="${2:-combined_wordlist.txt}"
TEMP_FILE=$(mktemp)
STATS_FILE=$(mktemp)
# Colors for output
RED='\033[0;31m'
GREEN='\033[0;32m'
YELLOW='\033[1;33m'
BLUE='\033[0;34m'
NC='\033[0m' # No Color
# Function to print colored output
print_status() {
echo -e "${BLUE}[INFO]${NC} $1"
}
print_success() {
echo -e "${GREEN}[SUCCESS]${NC} $1"
}
print_warning() {
echo -e "${YELLOW}[WARNING]${NC} $1"
}
print_error() {
echo -e "${RED}[ERROR]${NC} $1"
}
# Function to cleanup temp files
cleanup() {
rm -f "$TEMP_FILE" "$STATS_FILE"
}
# Set trap to cleanup on exit
trap cleanup EXIT
# Validate input directory
if [[ ! -d "$SEARCH_DIR" ]]; then
print_error "Directory '$SEARCH_DIR' does not exist!"
exit 1
fi
print_status "Starting wordlist combination process..."
print_status "Search directory: $SEARCH_DIR"
print_status "Output file: $OUTPUT_FILE"
# Find all .txt files recursively
print_status "Scanning for .txt files..."
mapfile -t txt_files < <(find "$SEARCH_DIR" -type f -name "*.txt" -readable) if [[ ${#txt_files[@]} -eq 0 ]]; then print_warning "No .txt files found in '$SEARCH_DIR'" exit 0 fi print_success "Found ${#txt_files[@]} .txt files" # Show found files echo print_status "Files to be processed:" for file in "${txt_files[@]}"; do size=$(stat -f%z "$file" 2>/dev/null || stat -c%s "$file" 2>/dev/null || echo "unknown")
lines=$(wc -l < "$file" 2>/dev/null || echo "0")
printf " %-50s %10s bytes, %8s lines\n" "$file" "$size" "$lines"
done
echo
read -p "Continue with combining these files? (y/N): " -n 1 -r
echo
if [[ ! $REPLY =~ ^[Yy]$ ]]; then
print_warning "Operation cancelled by user"
exit 0
fi
# Combine all files
print_status "Combining files..."
total_lines_before=0
file_count=0
for file in "${txt_files[@]}"; do
if [[ -r "$file" ]]; then
lines=$(wc -l < "$file") total_lines_before=$((total_lines_before + lines)) file_count=$((file_count + 1)) print_status "Processing: $file ($lines lines)" cat "$file" >> "$TEMP_FILE"
else
print_warning "Skipping unreadable file: $file"
fi
done
echo
print_success "Combined $file_count files with $total_lines_before total lines"
# Remove duplicates and count them
print_status "Removing duplicates..."
lines_before=$(wc -l < "$TEMP_FILE") # Sort and remove duplicates, preserving original line order for first occurrence sort "$TEMP_FILE" | uniq > "$OUTPUT_FILE"
lines_after=$(wc -l < "$OUTPUT_FILE") duplicates_removed=$((lines_before - lines_after)) # Generate statistics echo print_success "=== WORDLIST COMBINATION COMPLETE ===" echo printf "%-25s: %'d\n" "Files processed" "$file_count" printf "%-25s: %'d\n" "Total lines before" "$total_lines_before" printf "%-25s: %'d\n" "Lines after dedup" "$lines_after" printf "%-25s: %'d\n" "Duplicates removed" "$duplicates_removed" if [[ $total_lines_before -gt 0 ]]; then duplicate_percentage=$(( (duplicates_removed * 100) / total_lines_before )) printf "%-25s: %d%%\n" "Duplicate percentage" "$duplicate_percentage" fi echo printf "%-25s: %s\n" "Output file" "$OUTPUT_FILE" printf "%-25s: %s\n" "Output file size" "$(du -h "$OUTPUT_FILE" | cut -f1)" # Show sample of the output echo print_status "Sample from combined wordlist (first 10 lines):" head -10 "$OUTPUT_FILE" | sed 's/^/ /' echo print_status "Sample from combined wordlist (last 10 lines):" tail -10 "$OUTPUT_FILE" | sed 's/^/ /' # Check for empty lines empty_lines=$(grep -c '^$' "$OUTPUT_FILE" || echo "0") if [[ $empty_lines -gt 0 ]]; then echo print_warning "Found $empty_lines empty lines in the output file" read -p "Remove empty lines? (y/N): " -n 1 -r echo if [[ $REPLY =~ ^[Yy]$ ]]; then grep -v '^$' "$OUTPUT_FILE" > "$TEMP_FILE" && mv "$TEMP_FILE" "$OUTPUT_FILE"
new_lines=$(wc -l < "$OUTPUT_FILE")
print_success "Removed $empty_lines empty lines. New total: $new_lines lines"
fi
fi
# Final validation
if [[ -s "$OUTPUT_FILE" ]]; then
print_success "Combined wordlist successfully created: $OUTPUT_FILE"
else
print_error "Output file is empty! Something went wrong."
exit 1
fi
echo
print_status "You can now use this wordlist with John the Ripper:"
echo " ./john --format=KeePass --wordlist=$OUTPUT_FILE --fork=\$(nproc) Test3.hash"Save this script as combine_wordlists.sh and run it on the SecLists Passwords folder:
chmod +x combine_wordlists.sh
./combine_wordlists.sh SecLists/Passwords combined_wordlist.txt # the parameters are optional. Without them the script combines all *.txt files found in the current directory recursively into a combined_wordlist.txtRunning John the Ripper: CPU vs GPU Strategies
CPU-Based Cracking
For CPU-based attacks, use the standard KeePass format with wordlist and rules:
john --session=cpu --progress-every=30 --format=KeePass \
--wordlist=combined_wordlist.txt \
--rules=All \
--fork=$(nproc) \
database.hashGPU-Accelerated Cracking
For GPU acceleration with Argon2 support:
john --session=gpu --progress-every=30 \
--format=KeePass-Argon2-opencl \
--wordlist=combined_wordlist.txt \
--devices=0,1 \
database.hashSession Management
For long-running sessions, use John's session features. It's recommended to always use sessions.
# Start with session name
john --session=gpu --format=KeePass-Argon2-opencl database.hash
# Check status
john --status=gpu
# Resume if interrupted
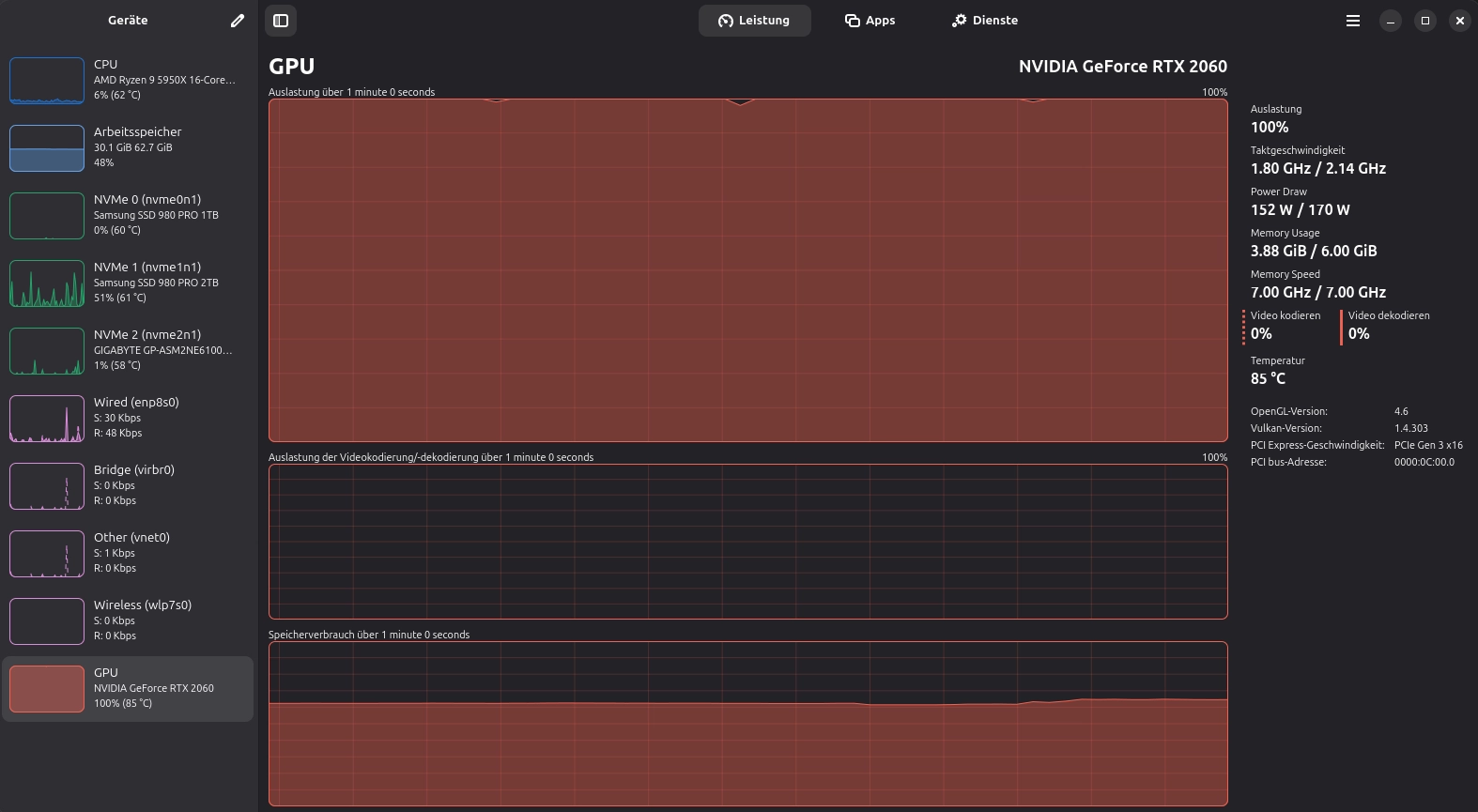
john --restore=gpuCheck system load
Check with a tool like Mission Center for the load on your CPU/GPU
Understanding John's Status Output
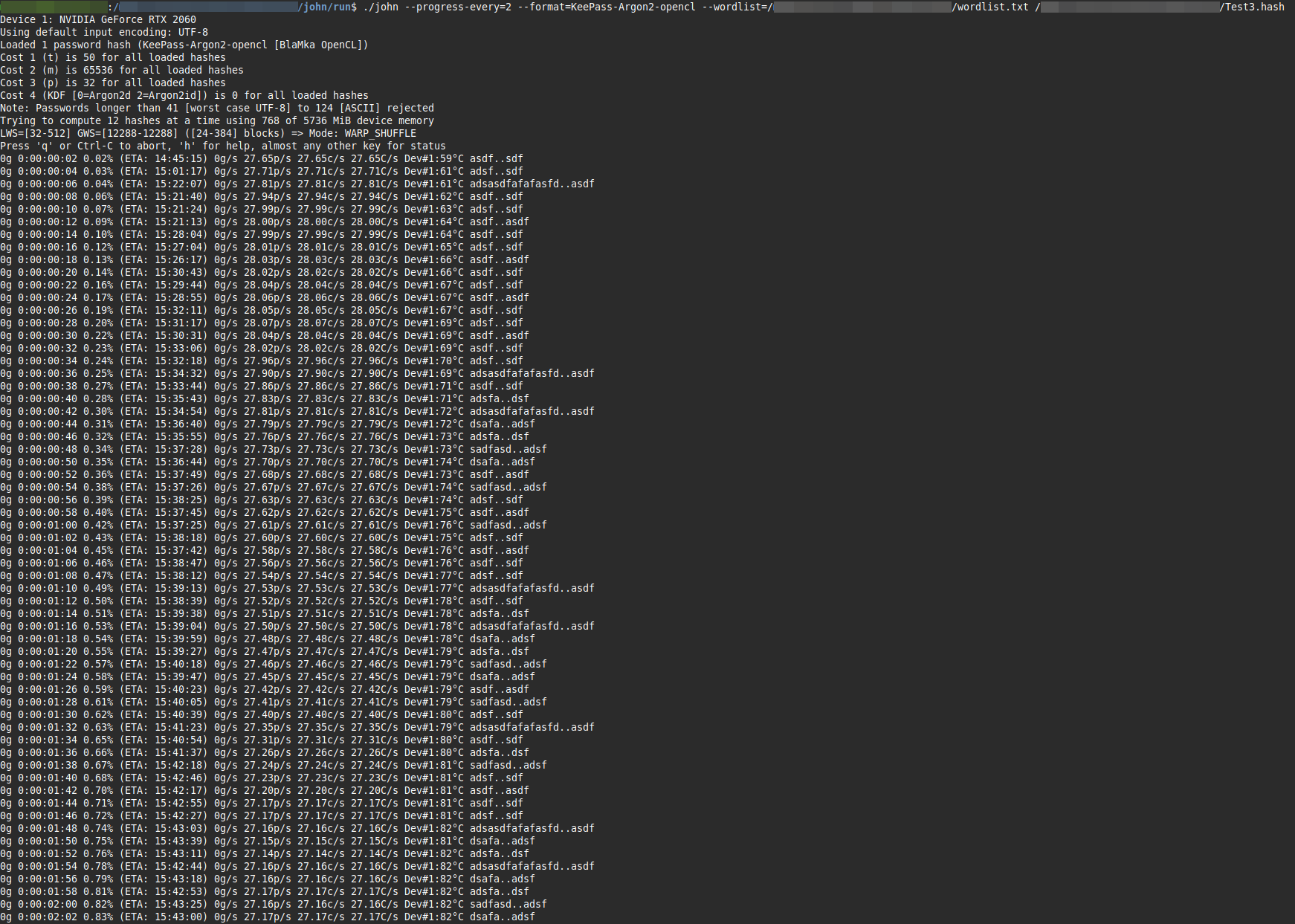
When running, John displays status updates like this (with parameter --progress-every=N or when pressing the 's' key):
0g 0:00:24:30 10.04% (ETA: 15:42:48) 0g/s 27.34p/s 27.34c/s 27.34C/s Dev#1:84°C dsafa..adsfKey metrics explained:
- 0g: Passwords cracked so far
- 27.34p/s: Passwords tested per second (typical for Argon2)
- Dev#1:84°C: GPU temperature (monitor for thermal throttling)
- ETA: Estimated completion time
Performance Comparison: KDBX4 vs Other Formats
| Hash Type | CPU Speed (AMD Ryzen 9 5950x 16 cores) | GPU Speed (NVIDIDA RTX 2060) | Time for 1M passwords |
|---|---|---|---|
| MD5 | 500M p/s | 50B p/s | < 1 second |
| SHA256 | 100M p/s | 10B p/s | < 1 second |
| bcrypt | 10K p/s | 100K p/s | 3 hours |
| KDBX4 (Argon2) | 5 p/s | 27 p/s | 10+ hours |
Optimizing CPU Threads: Physical Cores vs Hyperthreading for KDBX4
When running John the Ripper on a modern CPU with hyperthreading (e.g., 16 cores / 32 threads), a common question arises: should you use --fork=16 (physical cores only) or --fork=32 (all logical threads)?
The Short Answer: Test Both, But Physical Cores Usually Win
For KDBX4 cracking with Argon2, using only physical cores (--fork=16) typically performs 5-15% better than using all threads (--fork=32). This is because Argon2 is memory-intensive, and hyperthreads share cache and memory bandwidth with their sibling cores.
Simple Testing Method
Here's the easiest way to find your optimal setting:
# Test 1: Physical cores only (16 cores example)
john --fork=16 --format=KeePass --wordlist=wordlist.txt database.hash
# After 1 minute, check the speed:
john --status
# Note the p/s (passwords per second) value, then stop with Ctrl+C
# Test 2: All threads (32 threads)
john --fork=32 --format=KeePass --wordlist=wordlist.txt database.hash
# After 1 minute, check the speed:
john --status
# Compare the p/s values - higher is betterWhat to Look For in Status Output
When you run john --status, you'll see something like:
0g 0:00:01:00 0.05% (ETA: 12:34:56) 0g/s 5.2p/s 5.2c/s 5.2C/s password123..admin456The key metric is p/s (passwords per second). Compare this value between different fork settings.
Quick Test for Your System
Run this simple test to find your optimal setting in under 5 minutes:
# Get your CPU info
echo "Physical cores: $(lscpu | grep '^Core(s) per socket' | awk '{print $NF}')"
echo "Total threads: $(nproc)"
# Test different fork values (adjust based on your CPU)
for fork in 8 16 24 32; do
echo "Testing --fork=$fork..."
timeout 60 john --fork=$fork --format=KeePass --wordlist=wordlist.txt hash.txt &
sleep 45
john --status
pkill john
echo "---"
sleep 5
doneWhy Physical Cores Often Win
- Memory bandwidth: Argon2 needs lots of memory access; hyperthreads compete for the same memory channels
- Cache sharing: Hyperthreads share L1/L2 cache with their sibling core, causing contention
- Heat generation: Using all threads generates more heat, potentially causing CPU throttling
When to Use All Threads (--fork=32)
Consider using all threads only when:
- Cracking simpler hashes (MD5, NTLM, SHA1)
- Your system has exceptional cooling
- Testing shows it's actually faster for your specific setup
The Bottom Line
For KDBX4 cracking: start with --fork= set to your physical core count. Test with John's status output to verify. Most users will find physical cores only (e.g., --fork=16 on a 16-core CPU) gives the best performance for Argon2-based hashes.
Remember: a 10% performance difference might not sound like much, but when a wordlist takes 10 hours to complete, that's a full hour saved!
Optimization Strategies for KDBX4 Cracking
Wordlist Quality Over Quantity
Given the extremely slow speed of KDBX4 cracking, wordlist quality becomes paramount. Focus on:
- Targeted wordlists: Use passwords relevant to your target (personal info, company names, dates)
- Common passwords first: Start with top 10,000 most common passwords
- Minimal rules: Each rule multiplies cracking time significantly
- Remove duplicates: Our script handles this automatically
KDBX4 Cracking Strategies - From Simple to Advanced
These strategies are ordered from simplest to most complex implementation. Beginners should start with Strategy 1 and work their way up as they become more comfortable with John the Ripper.
Complexity Guide
| Complexity Level | Strategies | Skills Required |
|---|---|---|
| ⭐ Beginner | 1 | Basic terminal usage, understanding John commands |
| ⭐⭐ Beginner‑Intermediate | 2-3 | File splitting, parallel processing, basic scripting |
| ⭐⭐⭐ Intermediate | 4-5 | Masks, rules, timeout commands, process management |
| ⭐⭐⭐⭐ Intermediate‑Advanced | 6-8 | Advanced John features, config editing, statistical analysis |
| ⭐⭐⭐⭐⭐ Advanced/Expert | 9-12 | Bash scripting, networking, automation, queue management |
Strategy 1: Basic Parallel CPU and GPU Processing
Complexity: ⭐ (Beginner)
Run CPU and GPU attacks simultaneously on different wordlists to maximize hardware utilization:
# Terminal 1: GPU with common passwords
john --session=gpu1 --format=KeePass-Argon2-opencl --wordlist=top10000.txt database.hash
# Terminal 2: CPU with targeted wordlist
john --session=cpu1 --format=KeePass --wordlist=targeted.txt --fork=$(nproc) database.hash
# Terminal 3: GPU with incremental mode
john --session=gpu2 --format=KeePass-Argon2-opencl --incremental=Lower database.hash
# Terminal 4: CPU with rules
john --session=cpu2 --format=KeePass --wordlist=common.txt --rules=jumbo --fork=$(nproc) database.hashStrategy 2: Split Wordlist Across Multiple Processes
Complexity: ⭐⭐ (Beginner-Intermediate)
Divide large wordlists into chunks and run multiple John instances, each handling a portion. This prevents duplicate work and maximizes throughput:
# Split wordlist into 4 parts
split -n l/4 combined_wordlist.txt wordlist_part_
# Run 4 parallel instances with different parts
john --session=gpu1 --format=KeePass-Argon2-opencl --wordlist=wordlist_part_aa database.hash &
john --session=gpu2 --format=KeePass-Argon2-opencl --wordlist=wordlist_part_ab database.hash &
john --session=cpu1 --format=KeePass --fork=16 --wordlist=wordlist_part_ac database.hash &
john --session=cpu2 --format=KeePass --fork=16 --wordlist=wordlist_part_ad database.hash &
# Monitor all sessions
watch 'john --status=gpu1; john --status=gpu2; john --status=cpu1; john --status=cpu2'Strategy 3: Language-Specific Targeted Attacks
Complexity: ⭐⭐ (Beginner-Intermediate)
Use language-specific wordlists and rules for targeted attacks:
# Download language-specific wordlists
wget https://raw.githubusercontent.com/danielmiessler/SecLists/master/Passwords/Common-Credentials/10-million-password-list-top-100000.txt
wget https://raw.githubusercontent.com/danielmiessler/SecLists/master/Passwords/french_passwords.txt
wget https://raw.githubusercontent.com/danielmiessler/SecLists/master/Passwords/german_passwords.txt
# Run parallel attacks with different languages
john --session=gpu_english --format=KeePass-Argon2-opencl --wordlist=english_words.txt --rules=jumbo database.hash &
john --session=cpu_french --format=KeePass --fork=16 --wordlist=french_passwords.txt --rules=french database.hash &
john --session=cpu_german --format=KeePass --fork=16 --wordlist=german_passwords.txt --rules=german database.hash &
# Monitor progress
while true; do
clear
echo "=== English Attack (GPU) ==="
john --status=gpu_english
echo -e "\n=== French Attack (CPU) ==="
john --status=cpu_french
echo -e "\n=== German Attack (CPU) ==="
john --status=cpu_german
sleep 5
doneStrategy 4: Progressive Complexity Attack
Complexity: ⭐⭐⭐ (Intermediate)
Start with simple patterns and progressively increase complexity. This optimizes for common password patterns:
# Phase 1: Common passwords (1 hour)
timeout 1h john --session=gpu_phase1 --format=KeePass-Argon2-opencl --wordlist=top-100k.txt database.hash
# Phase 2: Short passwords (2 hours)
timeout 2h john --session=gpu_phase2 --format=KeePass-Argon2-opencl --incremental=Lower --min-length=1 --max-length=6 database.hash
# Phase 3: Common patterns with numbers (3 hours)
timeout 3h john --session=gpu_phase3 --format=KeePass-Argon2-opencl --mask='?l?l?l?l?d?d?d?d' database.hash
# Phase 4: Dictionary with rules (6 hours)
timeout 6h john --session=gpu_phase4 --format=KeePass-Argon2-opencl --wordlist=combined.txt --rules=best64 database.hash
# Phase 5: Full incremental (unlimited)
john --session=gpu_phase5 --format=KeePass-Argon2-opencl --incremental database.hashStrategy 5: Hybrid Dictionary + Mask Attack
Complexity: ⭐⭐⭐ (Intermediate)
Combine dictionary words with common suffixes/prefixes using mask attacks:
# Create base words file
head -10000 combined_wordlist.txt > base_words.txt
# Terminal 1: Words + years (2020-2024)
john --session=gpu_hybrid1 --format=KeePass-Argon2-opencl --wordlist=base_words.txt --mask='?w202[0-4]' database.hash
# Terminal 2: Words + special char + digits
john --session=cpu_hybrid1 --format=KeePass --fork=16 --wordlist=base_words.txt --mask='?w!?d?d' database.hash
# Terminal 3: Capitalized + numbers
john --session=cpu_hybrid2 --format=KeePass --fork=16 --wordlist=base_words.txt --rules=NT --mask='?w?d?d?d' database.hash
# Terminal 4: Leetspeak variations
john --session=cpu_hybrid3 --format=KeePass --fork=16 --wordlist=base_words.txt --rules=l33t database.hashStrategy 6: PRINCE Attack Mode
Complexity: ⭐⭐⭐⭐ (Intermediate-Advanced)
PRINCE (PRobability INfinite Chained Elements) combines words from wordlist in intelligent ways:
# Prepare PRINCE wordlist (smaller is better)
head -5000 combined_wordlist.txt > prince_base.txt
# Run PRINCE attack with different configurations
# Terminal 1: 2-word combinations
john --session=gpu_prince1 --format=KeePass-Argon2-opencl --prince=prince_base.txt --prince-length=2 database.hash
# Terminal 2: 3-word combinations with case mutations
john --session=cpu_prince1 --format=KeePass --fork=16 --prince=prince_base.txt --prince-length=3 --prince-case-permute database.hash
# Terminal 3: PRINCE with rules
john --session=cpu_prince2 --format=KeePass --fork=16 --prince=prince_base.txt --rules=wordlist database.hashStrategy 7: Markov Chain Statistical Attack
Complexity: ⭐⭐⭐⭐ (Intermediate-Advanced)
Use Markov chains to generate statistically probable passwords based on training data:
# Generate Markov statistics from existing passwords
./calc_stat combined_wordlist.txt markov_stats
# Run Markov mode with different length targets
# Terminal 1: Length 8-10 passwords
john --session=gpu_markov1 --format=KeePass-Argon2-opencl --markov=200:0:0:8-10 --markov-stats=markov_stats database.hash
# Terminal 2: Length 11-12 passwords
john --session=cpu_markov1 --format=KeePass --fork=16 --markov=200:0:0:11-12 --markov-stats=markov_stats database.hash
# Terminal 3: Length 6-7 with higher threshold
john --session=cpu_markov2 --format=KeePass --fork=16 --markov=250:0:0:6-7 --markov-stats=markov_stats database.hashStrategy 8: Custom Character Set Incremental
Complexity: ⭐⭐⭐⭐ (Intermediate-Advanced)
Define custom character sets based on password policy or known patterns:
# Edit john.conf to add custom character sets
echo '
[Incremental:Corporate]
File = $JOHN/corporate.chr
MinLen = 8
MaxLen = 14
CharCount = 69
[Incremental:Corporate:charset]
ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789!@#$%
' >> ~/.john/john.conf
# Generate custom .chr file from corporate passwords
john --make-charset=corporate.chr --wordlist=corporate_passwords.txt
# Run with custom charset
john --session=gpu_custom1 --format=KeePass-Argon2-opencl --incremental=Corporate database.hash
# Parallel: Different length ranges
john --session=cpu_custom1 --format=KeePass --fork=8 --incremental=Corporate --min-length=8 --max-length=10 database.hash &
john --session=cpu_custom2 --format=KeePass --fork=8 --incremental=Corporate --min-length=11 --max-length=14 database.hash &Strategy 9: Time-Based Rotation with Checkpoints
Complexity: ⭐⭐⭐⭐⭐ (Advanced)
Rotate through different attack strategies automatically, saving progress:
#!/bin/bash
# Auto-rotation script
HASH="database.hash"
RUNTIME=3600 # 1 hour per strategy
strategies=(
"--wordlist=top-passwords.txt"
"--wordlist=leaked-passwords.txt --rules=dive"
"--incremental=Alnum --max-length=8"
"--mask='?u?l?l?l?l?d?d?s'"
"--prince=common-words.txt"
)
for i in "${!strategies[@]}"; do
echo "Starting strategy $((i+1)): ${strategies[$i]}"
timeout $RUNTIME john --session=gpu_rotation_$i --format=KeePass-Argon2-opencl ${strategies[$i]} $HASH
# Check if password was found
if john --show $HASH | grep -q "1 password hash cracked"; then
echo "Password found!"
break
fi
# Save checkpoint
cp ~/.john/gpu_rotation_$i.rec ~/.john/backup_gpu_rotation_$i.rec
doneStrategy 10: Distributed Network Cracking
Complexity: ⭐⭐⭐⭐⭐ (Advanced)
Distribute the workload across multiple machines on your network:
# On coordinator machine, split wordlist by number of nodes
NODES=5
split -n l/$NODES combined_wordlist.txt node_
# Copy hash file to all nodes
for i in {1..5}; do
scp database.hash node$i:/tmp/
scp node_a$i node$i:/tmp/wordlist.txt
done
# Start cracking on each node via SSH
ssh node1 "cd /path/to/john/run && ./john --session=gpu_node1 --format=KeePass-Argon2-opencl --wordlist=/tmp/wordlist.txt /tmp/database.hash" &
ssh node2 "cd /path/to/john/run && ./john --session=cpu_node2 --format=KeePass --fork=32 --wordlist=/tmp/wordlist.txt /tmp/database.hash" &
ssh node3 "cd /path/to/john/run && ./john --session=gpu_node3 --format=KeePass-Argon2-opencl --wordlist=/tmp/wordlist.txt /tmp/database.hash" &
ssh node4 "cd /path/to/john/run && ./john --session=cpu_node4 --format=KeePass --fork=32 --wordlist=/tmp/wordlist.txt /tmp/database.hash" &
ssh node5 "cd /path/to/john/run && ./john --session=cpu_node5 --format=KeePass --fork=32 --wordlist=/tmp/wordlist.txt /tmp/database.hash" &
# Collect results
for i in {1..5}; do
ssh node$i "cd /path/to/john/run && ./john --show /tmp/database.hash"
doneStrategy 11: Smart Queue Management
Complexity: ⭐⭐⭐⭐⭐ (Expert)
Implement intelligent queue management based on success probability:
#!/bin/bash
# Smart queue manager for KDBX4 cracking
HASH="database.hash"
GPU_FORMAT="KeePass-Argon2-opencl"
CPU_FORMAT="KeePass"
# Priority queue (highest probability first)
declare -a high_priority=(
"--wordlist=known_user_passwords.txt"
"--wordlist=company_specific.txt"
"--wordlist=top_10k_passwords.txt"
)
declare -a medium_priority=(
"--wordlist=rockyou_top100k.txt --rules=best64"
"--incremental=Lower --max-length=8"
"--mask='?l?l?l?l?d?d?d?d'"
)
declare -a low_priority=(
"--wordlist=full_rockyou.txt"
"--incremental"
"--mask='?a?a?a?a?a?a?a?a'"
)
# Function to run attack with timeout
run_attack() {
local session=$1
local timeout=$2
local format=$3
local options=$4
echo "[$(date)] Starting: john --session=$session --format=$format $options"
timeout $timeout john --session=$session --format=$format $options $HASH
# Check success
if john --show $HASH | grep -q "1 password hash cracked"; then
echo "[$(date)] PASSWORD FOUND!"
return 0
fi
return 1
}
# Execute priority queues
echo "Starting high priority attacks..."
for i in "${!high_priority[@]}"; do
run_attack "gpu_high_$i" 1800 $GPU_FORMAT "${high_priority[$i]}" && exit 0
done
echo "Starting medium priority attacks..."
for i in "${!medium_priority[@]}"; do
run_attack "gpu_medium_$i" 3600 $GPU_FORMAT "${medium_priority[$i]}" && exit 0
done
echo "Starting low priority attacks..."
for i in "${!low_priority[@]}"; do
run_attack "cpu_low_$i" 7200 $CPU_FORMAT "--fork=32 ${low_priority[$i]}" && exit 0
done
echo "All strategies exhausted without success"Strategy 12: MPI Cluster-Based Distributed Cracking
Complexity: ⭐⭐⭐⭐⭐ (Expert)
Use John's native MPI (Message Passing Interface) support for true distributed computing across multiple nodes with automatic work distribution and no duplicate effort:
# Prerequisites: Install MPI on all nodes
# On each node:
sudo apt install openmpi-bin libopenmpi-dev
# Compile John with MPI support (on all nodes or shared NFS)
cd john/src
./configure --enable-mpi --enable-opencl
make -j$(nproc) clean && make -j$(nproc)
# Create MPI hostfile with node specifications
cat > ~/mpi_hosts << 'EOF' # Format: hostname slots=cores gpu-node1 slots=8 # GPU node with 8 cores gpu-node2 slots=8 # GPU node with 8 cores cpu-node1 slots=32 # CPU node with 32 cores cpu-node2 slots=32 # CPU node with 32 cores cpu-node3 slots=16 # CPU node with 16 cores EOF # Set up SSH keys for passwordless access between nodes ssh-keygen -t rsa -N "" -f ~/.ssh/mpi_key for node in gpu-node1 gpu-node2 cpu-node1 cpu-node2 cpu-node3; do ssh-copy-id -i ~/.ssh/mpi_key.pub $node done # Test MPI connectivity mpirun --hostfile ~/mpi_hosts --map-by node hostname # Run distributed KDBX4 cracking with MPI # Basic distributed attack mpirun --hostfile ~/mpi_hosts -np 96 ./john \ --session=mpi_cluster \ --format=KeePass \ --wordlist=combined_wordlist.txt \ database.hash # Advanced MPI with GPU nodes (separate MPI groups) # For GPU nodes - using OpenCL format mpirun --host gpu-node1,gpu-node2 -np 16 ./john \ --session=mpi_gpu \ --format=KeePass-Argon2-opencl \ --wordlist=top_priority.txt \ database.hash & # For CPU nodes - using threading mpirun --host cpu-node1,cpu-node2,cpu-node3 -np 80 ./john \ --session=mpi_cpu \ --format=KeePass \ --wordlist=extended_list.txt \ --rules=jumbo \ database.hash & # MPI with node-specific optimization cat > mpi_launch.sh << 'EOF' #!/bin/bash # Intelligent MPI launcher with node detection HASH="database.hash" HOSTFILE="~/mpi_hosts" # Detect node capabilities detect_nodes() { for node in $(cat $HOSTFILE | grep -v '^#' | awk '{print $1}'); do if ssh $node "nvidia-smi &>/dev/null"; then
echo "$node:GPU"
else
echo "$node:CPU"
fi
done
}
# Launch appropriate format per node type
launch_mpi() {
# Get GPU nodes
GPU_NODES=$(detect_nodes | grep GPU | cut -d: -f1 | tr '\n' ',')
CPU_NODES=$(detect_nodes | grep CPU | cut -d: -f1 | tr '\n' ',')
# Launch GPU nodes with OpenCL
if [ ! -z "$GPU_NODES" ]; then
mpirun --host ${GPU_NODES%,} ./john \
--session=mpi_gpu_cluster \
--format=KeePass-Argon2-opencl \
--wordlist=priority_words.txt \
$HASH &
echo "Launched MPI on GPU nodes: $GPU_NODES"
fi
# Launch CPU nodes with fork
if [ ! -z "$CPU_NODES" ]; then
mpirun --host ${CPU_NODES%,} ./john \
--session=mpi_cpu_cluster \
--format=KeePass \
--fork=4 \
--wordlist=full_wordlist.txt \
--rules=best64 \
$HASH &
echo "Launched MPI on CPU nodes: $CPU_NODES"
fi
}
launch_mpi
EOF
chmod +x mpi_launch.sh
./mpi_launch.sh
# Monitor MPI cluster status
watch -n 2 'echo "=== MPI Cluster Status ===";
mpirun --hostfile ~/mpi_hosts john --status=mpi_cluster 2>/dev/null;
echo;
echo "=== Node Load ===";
for node in $(cat ~/mpi_hosts | grep -v "^#" | awk "{print \$1}"); do
echo -n "$node: ";
ssh $node "uptime | awk -F\"load average:\" \"{print \\$2}\"";
done'
# Advanced MPI features for KDBX4
# Use MPI with dynamic load balancing
mpirun --hostfile ~/mpi_hosts \
--mca btl_tcp_if_include eth0 \
--bind-to core \
--map-by slot \
-np 96 \
./john \
--session=mpi_balanced \
--format=KeePass \
--wordlist=huge_list.txt \
--node=1-96/SYNC \
database.hash
# MPI with checkpoint/restart capability
mpirun --hostfile ~/mpi_hosts \
--mca crs_base_snapshot_dir /shared/checkpoints \
--gmca crs self \
-am ft-enable-cr \
-np 96 \
./john \
--session=mpi_checkpoint \
--format=KeePass \
--wordlist=massive_list.txt \
database.hash
# Collect results from all nodes
for node in $(cat ~/mpi_hosts | grep -v '^#' | awk '{print $1}' | sort -u); do
echo "=== Results from $node ==="
ssh $node "cd john/run && ./john --show database.hash 2>/dev/null"
done | grep -v "0 password hashes cracked"MPI Performance Optimization for KDBX4:
#!/bin/bash
# MPI Performance Tuning Script for KDBX4
# Set optimal MPI environment variables
export OMPI_MCA_btl_openib_allow_ib=1 # Enable InfiniBand if available
export OMPI_MCA_btl_tcp_if_include=eth0 # Specify network interface
export OMPI_MCA_mpi_yield_when_idle=1 # Reduce CPU usage when waiting
export OMPI_MCA_hwloc_base_binding_policy=core # Bind processes to cores
# Calculate optimal process distribution for KDBX4
# Given ~27 p/s on GPU and ~5 p/s on CPU
calculate_distribution() {
local gpu_nodes=$1
local cpu_nodes=$2
local cpu_cores_per_node=$3
# For KDBX4, fewer processes with more memory is better
# due to Argon2's memory requirements
echo "Optimal MPI Distribution for KDBX4:"
echo "GPU Nodes: $gpu_nodes nodes × 2 processes = $((gpu_nodes * 2)) GPU processes"
echo "CPU Nodes: $cpu_nodes nodes × 4 processes = $((cpu_nodes * 4)) CPU processes"
echo "Total MPI Processes: $((gpu_nodes * 2 + cpu_nodes * 4))"
echo "Expected combined rate: ~$((gpu_nodes * 27 + cpu_nodes * 5)) p/s"
}
# Example: 2 GPU nodes, 4 CPU nodes
calculate_distribution 2 4 32
# Launch with optimized settings
mpirun --hostfile ~/mpi_hosts \
--mca btl self,tcp \
--mca btl_tcp_links 4 \
--bind-to core \
--report-bindings \
-np 12 \
./john \
--session=mpi_optimized \
--format=KeePass \
--wordlist=targeted_list.txt \
database.hash 2>&1 | tee mpi_cluster.logPerformance Monitoring Script (Supporting Tool)
Complexity: ⭐⭐⭐ (Intermediate)
Monitor and log performance across all strategies:
#!/bin/bash
# Performance monitor for parallel John sessions
LOG_FILE="kdbx4_cracking.log"
HASH_FILE="database.hash"
# Function to get session stats
get_stats() {
local session=$1
john --status=$session 2>/dev/null | grep -E "g/s|p/s|c/s|ETA"
}
# Main monitoring loop
while true; do
clear
echo "=== KDBX4 Cracking Monitor - $(date) ==="
echo "================================================"
# Check if password found
if john --show $HASH_FILE 2>/dev/null | grep -q "1 password hash cracked"; then
echo "*** PASSWORD FOUND! ***"
john --show $HASH_FILE
break
fi
# Get all running sessions - separate GPU and CPU
echo -e "\n=== GPU Sessions ==="
for session in $(ls ~/.john/gpu*.rec 2>/dev/null | xargs -n1 basename | sed 's/.rec//'); do
echo -e "\nSession: $session"
get_stats $session
done
echo -e "\n=== CPU Sessions ==="
for session in $(ls ~/.john/cpu*.rec 2>/dev/null | xargs -n1 basename | sed 's/.rec//'); do
echo -e "\nSession: $session"
get_stats $session
done
# System stats
echo -e "\n=== System Stats ==="
echo "CPU Usage: $(top -bn1 | grep "Cpu(s)" | awk '{print $2}')"
echo "Memory: $(free -h | grep Mem | awk '{print $3 "/" $2}')"
# GPU stats (NVIDIA)
if command -v nvidia-smi &> /dev/null; then
echo "GPU Temp: $(nvidia-smi --query-gpu=temperature.gpu --format=csv,noheader)°C"
echo "GPU Usage: $(nvidia-smi --query-gpu=utilization.gpu --format=csv,noheader)"
fi
# Log to file
gpu_sessions=$(ls ~/.john/gpu*.rec 2>/dev/null | wc -l)
cpu_sessions=$(ls ~/.john/cpu*.rec 2>/dev/null | wc -l)
echo "[$(date)] GPU sessions: $gpu_sessions, CPU sessions: $cpu_sessions" >> $LOG_FILE
sleep 10
doneAlternative Tools Comparison
| Feature | John the Ripper | Hashcat | KeePass itself |
|---|---|---|---|
| KDBX4 Support | Yes | No | Yes (but useless for our case) |
| GPU Acceleration | Yes | Yes | No |
| Multi-threading | Yes | Yes | No |
| Argon2 Performance | Good | Better | Slow |
| Rule Support | Excellent | Good | No |
Troubleshooting Common Issues
OpenCL Detection Problems
If John doesn't detect your GPU:
# Check OpenCL devices
clinfo
# List John's detected devices
./john --list=opencl-devices
# Force specific platform
./john --format=KeePass-Argon2-opencl --platform=0 database.hashMemory Issues with Argon2
KDBX4's Argon2 requires significant RAM. If encountering memory errors:
# Reduce parallel threads
john --format=KeePass --fork=4 database.hash
# For GPU, limit work size
john --format=KeePass-Argon2-opencl --lws=32 --gws=256 database.hashTemperature Management
Monitor GPU temperature to prevent throttling:
# NVIDIA monitoring
watch -n 1 nvidia-smi
# AMD monitoring
watch -n 1 rocm-smi
# Reduce temperature by limiting GPU usage
john --format=KeePass-Argon2-opencl --devices=0 --lws=16 database.hashConclusion
Cracking KDBX4 KeePass databases represents one of the most challenging tasks in password recovery due to Argon2's deliberate resistance to acceleration. While modern GPUs might crack billions of MD5 hashes per second, KDBX4 limits even high-end hardware to mere dozens of attempts per second. This guide has equipped you with the knowledge and tools to approach this challenge efficiently, from compiling John with OpenCL support to optimizing wordlists and managing parallel CPU/GPU attacks.
Remember that success in KDBX4 cracking depends more on wordlist quality than raw computing power. Focus on targeted, relevant passwords rather than exhaustive brute-force approaches. With patience and the right strategy, recovering a forgotten KeePass master password is possible, though the intentionally slow speed serves as a reminder of why KeePass remains one of the most secure password management solutions available.
Always ensure you have proper authorization before attempting to crack any password database, and use these techniques responsibly for legitimate purposes such as recovering your own passwords or authorized security testing.